Using Q-Learning To Play The Snake Game
Q-Learning
Reinforcement Learning is an area within Machine Learning that concerns instructing AI agents to make optimal/near optimal actions within the given environment by controlling reward functions at different states of the environment. It is one of the three basic Machine Learning paradigms, alongside Supervised and Unsupervised Learning. Similarly to its counterparts, Reinforcement Learning works by seeking to optimize its objective function, specifically the AI agents will try to maximize their cumulative rewards. Yet different from its counterparts, designing Reinforcement Learning algorithms focuses on finding the balance between exploration (trying out unrecorded states) and exploitation (maximizing current known rewards).
Reinforcement Learning can be categorized in many ways, one common way is through separating on-policy and off-policy algorithms. A policy π(s) determines the probability distribution of all possible actions at a given state s. The agent will then make the action based on this policy. On-policy algorithms try to improve upon the policy that is used to make decisions, while off-policy ones try to figure out the optimal strategy without considering the decision-making policy. On-policy is useful to improve the exploration process of the agent to encourage good explorations, and off-policy is more suitable for more deterministic, exploitation focused algorithms.
Q-Learning is a commonly used algorithm in Reinforcement Learning due to its simplicity in form and concept, yet still very effective for many types of problems and is still relevant to this day. Q-Learning is an off policy reinforcement learning algorithm that seeks to find the best action to take given the current state. It is considered to be off-policy because the Q function learns from actions taken outside the policy. Specifically, it seeks to maximize the cumulative rewards.

The Q function plays the main role in this algorithm. In an optimal situation, the Q function formula at a state s, with action a chosen, will be:

Where s’ is the future state, a’ is the best action at that future state, and r(s,a) is the reward for taking action a at state s (can be negative). We can use this formula as a goal to reach to get the final update formula:

Here α is the learning rate. This update formula will be used to update the Q function in our snake game algorithm.
Snake Game Implementation
I implemented the algorithm in Python. I used one of the gym snake game environment that is custom made (available in github repository) that renders the game much faster and smoother than the default one that you can download using pip.
In this environment, I did not use the map itself as a state. While it is theoretically possible to find an optimal strategy for this game using reinforcement learning, the possible number of states in the game is exponentially high as the snake can get to hundreds of tiles long, with countless positional variations for the snake. Thus, it is impractical to use this default state for Q-Learning.
Instead, another strategy I used was displaying the state as a list of 6 numbers. This strategy has been used before and proved to be quite effective in the short-term. The first 4 numbers are binaries, which represent whether the 4 directions from the snake head will encounter a wall (the snake’s body also counts), which encourages the snake to avoid that direction. The fifth numbers will determine whether the snake is left, same column, or right of the fruit’s position, represented by 1,0,-1, respectively. The sixth number behaves similarly, but for up, same row, down, instead. The final two numbers allow us to nudge the snake towards the fruit using some tricks, such as what I did below:
if last_state[4] == 0 and state[4] != 0:
reward -= 10
if last_state[4] != 0 and state[4] == 0:
reward += 10
if last_state[5] == 0 and state[5] != 0:
reward -= 10
if last_state[5] != 0 and state[5] == 0:
reward += 10
if action == 0 and state[4] == -1:
reward += 10
if action == 1 and state[4] == 1:
reward += 10
if action == 3 and state[5] == -1:
reward += 10
if action == 2 and state[5] == 1:
reward += 10This encourages the snake to head closer towards the fruit. This strategy also has the advantage of a small number of states, which is only ²⁴*³²=144 states instead of possibly millions of states if we used the default state. This allows the algorithm to converge within a reasonable amount of time.
This is not to say, the algorithm doesn’t have any drawbacks of its own. As you might have noticed, this strategy will no longer works when there are walls blocking its intended route.
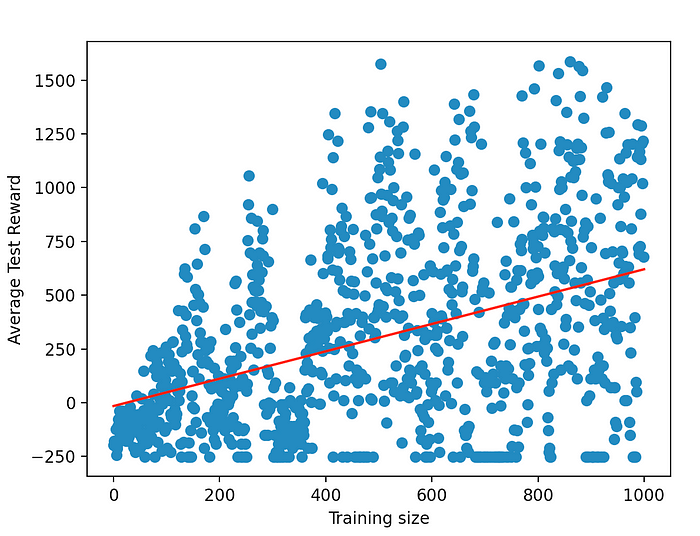
Still, this Q-learning implementation showed some promising results. Only after 1000 trained game, ran in less than a minute, the snake manages to reach 678.2 rewards on average, which means it eats a bit less than 7 fruits on average before dying. As we continue to update the Q function table (its data can be saved), the results will become more and more accurate.
We also compare this algorithm with a simple BFS algorithm search for the fruit using the Breath First Search algorithm. It’s not surprising that this algorithm outperforms the Q-Learning counterpart without needing any training, achieving 3239 rewards on average from the start. This is because as long as their is a route to reach the fruit, the snake agent will reach it, and only dies when it manages to trap itself. The Q-learning algorithm is far more limited.
Nevertheless, this small experiment shows some potentials of Q-learning, it can achieve pretty good results within a short amount of time as long as the number of states is not too high. I hope this implementation of Q-learning will inspire you readers to achieve some more useful results in other fields with this simple tool.
Link to the github file can be found here.